EKS vs. GKE Networking
This is the second post in my series about how AWS’ Elastic Kubernetes Service (EKS) and GCP’s Google Kubernetes Engine (GKE) differ. In my previous post, I looked at IAM from Pods both within their own cloud as well as cross-cloud between AWS and GCP — https://medium.com/@jason-umiker/cross-cloud-identities-between-gcp-and-aws-from-gke-and-or-eks-182652bddadb. In this post we’ll be looking at how the networking and its various settings differs between the two.
One of the first things that you’ll hit when you try to spin up the other managed Kubernetes in the other cloud is what parameters/settings you need to specify — especially re: the networking. This is especially true when you need to get the subnets created and/or CIDRs allocated by another team — and so need to explain to them what you need from them and wait for them before you can even get started — and if there is miscommunications/misunderstandings here it can really delay things.
Also, I find that some of the biggest differences between EKS and GKE (as well as the underlying AWS and GCP) are in their differing approaches to networking. So, this is at the heart of any true comparison of the two services.
Let’s get started!
AWS vs. GCP Virtual Private Cloud (VPC) networking
Some of the differences between the way that networking works on these two Kubernetes offerings comes down to the differences between the managed Virtual Private Clouds (VPC) offered by each provider.
These are the main differences that I think are relevant between the two clouds:
- In AWS, VPCs are regional (confined to one region) whereas, in GCP, VPCs are global
- In AWS, a VPC has one or more CIDRs assigned to it that the subnets within it need to fall within whereas, in GCP, the VPC itself has no CIDR(s) (only the subnets do)
- In AWS, subnets are zonal (are confined to a single Availability Zone (AZ)) whereas, in GCP, subnets are regional (across all the Zones in that region)
- This means that you generally will have fewer and larger subnets in GCP than you would in AWS - In AWS, you have public vs. private subnets (based on whether their default route is an Internet Gateway (IGW) or a NAT Gateway) whereas, in GCP, the subnet config stays the same either way — and you just choose to either assign a public IP or not to each resource to decide whether it is public or private
- In GCP, there is (of course) also a firewall involved (at the VPC level) that you can use to block public access as well as Organizational Policies you can configure to limit the ability to turn on public IPs for resources to keep certain subnets or resources ‘private’. - In AWS, your firewall options are Network Access Control Lists (NACLs) assigned to subnets and Security Groups assigned to resources whereas, in GCP, there are just firewall rules assigned to the VPC
- In AWS, Security Group rules can reference other Security Group IDs for dynamic rules not based on IP/CIDR (e.g. you allow the application’s AWS SG ID ingress access on the database’s AWS SG) whereas, in GCP, you put Tags on your resources and can reference those in the Firewall rules to allow for it to be similarly dynamic/micro-segmented in its firewalling - In AWS, to access AWS APIs on private IPs, you generally need to configure a VPC endpoint for each service whereas, in GCP, you enable a setting on each subnet called Private Google Access
- In GCP, you can choose between regional and global routing on a VPC
- In GCP, VPCs have an optional “auto” mode which will create a single /20 (4,096 IP) subnet in every region, with each region’s CIDR coming from a pre-determined set of IP CIDRs — all of which fall within the
10.128.0.0/9block (10.128.0.1–10.255.255.254)
- Both the limited 4096 IPs per region as well as the fact it takes the upper half of the huge 10.0.0.0/8 private IP range (that you ideally would need to evacuate to avoid overlap in any of your other environments) means this usually isn’t a good choice for many larger or more established businesses — but it is a fast and easy way to get started in a startup.
I’m sure there are other differences between the two — but those are the main ones I’ve encountered in my exploration so far that would impact setting up EKS vs. GKE.
EKS VPC CNI vs. GKE Dataplane V2
Both EKS’s default networking (the VPC CNI) as well as GKE’s (Dataplane v2) use ‘real’ VPC IPs for their Pods as well as their Nodes. The big difference between the two is the different subnetting and IP allocations involved.
EKS Networking
With EKS by default, you give the cluster a list of subnet IDs to run in (usually 3 — one per AZ). The network CIDRs of these are implied (you give EKS the AWS Subnet IDs — you don’t need to give it any CIDRs directly). Then it puts all three things into those same subnets together in the same flat network:
- The EKS Control Plane endpoints
- The Nodes
- The Pods
Subnet sizing
So, when picking the sizing, you usually would take the maximum number of Nodes and Pods (plus a bit of margin for the control plane and VPC endpoints and ALB-based Ingresses etc.) , divide that by 3 AZs and then round up to the smallest CIDR that will fit. For example, lets say we think we need at most 100 Nodes running up to 50 Pods each:
- 100 Nodes x 50 Pods each = 100 Node IPs + 5,000 Pod IPs = 5,100
- Maybe a 10% margin for other things using the subnet(s) to be extra safe = 5,610 IPs
- Divide that by 3 (across 3 AZs) = 1,870 IPs
- A /22 is 1,022 IPs (too small) and a /21 is 2,046 (too big — but the smallest that meets our needs) — 3 x /21s it is!
There’s an optional parameter which this time is a CIDR (rather than a subnet ID)— the one for the Kubernetes Services and their ClusterIPs. They are the Layer 3 load balancers built into Kubernetes — and they’re not route-able outside the cluster. But, if they overlap with an IP outside the cluster that your Pods need to talk to, it can cause problems. By default, EKS will pick a CIDR that doesn’t overlap with anything in the AWS VPC that it is located in — but it doesn’t know about the rest of your network and so can still pick one that overlaps with something important. To prevent that, you can now optionally specify one you are sure is safe.
Also, there is an optional feature to put the Pods in a different set of AWS VPC subnets than the Nodes called custom networking. This makes EKS a bit similar to GKE by separating out the Pods (as you’ll see in the next section). In my experience, this approach isn’t super common in EKS but, rather, one some customers are forced into due to constraints around available private IP CIDRs in their organizations or when they underestimated the IPs required for a cluster and need to grow it. I’ll touch on it a bit more in a later section on advanced configurations.
GKE Networking
Unlike EKS, with GKE Nodes and Pods go into separate and non-overlapping CIDR ranges. Though those different CIDRs are actually part of the same subnet with GKE, though. And also, by default, you’ll need to allow for a /24 allocation per Node for it’s Pods in the Pod range! Let’s dig into this in more detail:
Subnet Sizing
Firstly you pick a Node subnet in a GCP VPC for your GKE cluster. Let’s say you have one that is a /20 (the default for each region in the ‘auto’ mode) — that is 4092 usable addresses. This is where your Nodes will go — but it also will be used for, and can be shared with, other things like the GKE control plane, internal load balancers, some VMs on Compute Engine, etc.
So far we’re at just one VPC subnet ID to point GKE at for our new cluster— as opposed to three we had in EKS (since the subnet is regional rather than zonal). Sounds good!
But what about the Pods? Google requires you to specify a secondary IP range/CIDR that it’ll add to our subnet (that can’t overlap with the primary one) for our Pods. And GKE, by default, reserves a new /24 allocation for each Node’s Pods out of that as each Node launches! They say they do this because “having more than twice as many available IP addresses as the maximum number of Pods that can be created on a node allows Kubernetes to reduce IP address reuse as Pods are added to and removed from a Node.”
So, if we chose the same /20 sizing for the Pod CIDR (which seems pretty big at 4,092 addresses at first glance) that would only allow 16 Nodes (the number of /24s you can get within it)! This is why the default sizing that the GKE UI suggests for the Pod CIDR range is a /17 (allowing 128 Nodes).
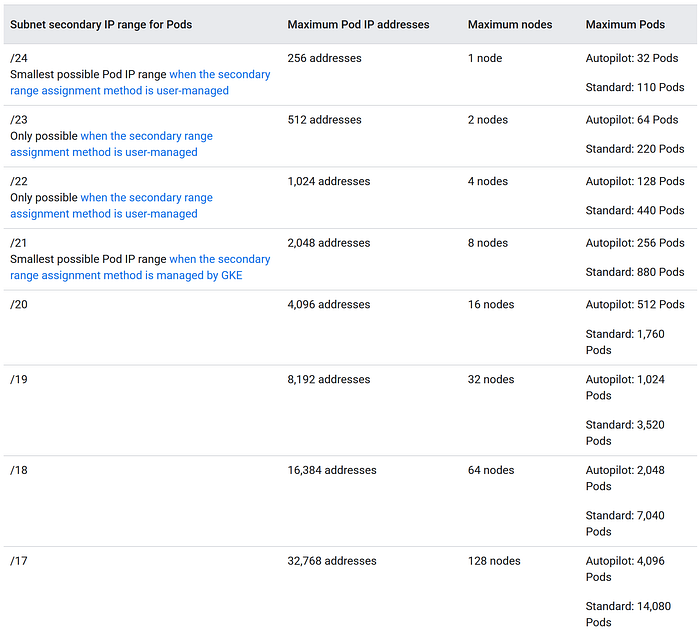
That /24 per Node CIDR is configurable — and if you’re running many small Nodes (and therefore not running many Pods on each) it’d make sense to decrease it. But note that this will decrease the maximum number of Pods you can launch on the Nodes. As a matter of fact, the setting for GKE doesn’t ask the CIDR size directly — but the maximum number of Pods you want to run. It then lowers (or raises) the Pod CIDR allocation per node based on that as follows:

What about the CIDR for Kubernetes Services? Starting with GKE Autopilot clusters running version 1.27 and later, and GKE Standard clusters running version 1.29 and later, GKE assigns IP addresses for GKE Services from a GKE-managed range of 34.118.224.0/20 by default. And being a 34.XXX address it won’t overlap with your own network. But you can still also specify your own secondary CIDR for them if you want to — which will work similarly to the Pod CIDR.
I’ve found many people are still specifying them as they have Terraform etc. that predated these versions when it was not an optional parameter (even though now it is — and not specifying it leads to it being more managed and saving you the IP space).
More advanced topics (IPv4 Exhaustion, IPv6)
Extending the Node and/or Pod address space with non-continuous subnets/CIDRs
Let’s say that you underestimated the sizing and now need to grow it.
In the case of EKS, you can move the Pods out from the same subnet as the Nodes to their own subnets by enabling Custom Networking as documented here. That would then also free up space in the original subnet for more Nodes (or other services sharing it that need IPs) as well as the Pods migrate out to their new home.
Unfortunately, though, you can’t have more than one subnet per AZ with EKS Custom Networking today — https://github.com/aws/containers-roadmap/issues/1709.
In the case of GKE, though, you can add additional and non-contiguous Pod CIDRs as documented here. There are a few catches (it only applies the new ranges to new Node Pools after you apply the change etc.) but it means you can start smaller knowing that you can expand later if needed — and by adding several smaller (presumably easier to come by) CIDR blocks too.
Note that you can’t extend the primary Node CIDR range on the subnet the same way though — so that one is more important to get right re: sizing.
Leveraging non-RFC1918 Pod CIDRs
In the case of both EKS and GKE, it is possible to configure them to have separate Pod subnets or CIDRs (and as discussed above in GKE it is actually required).
One option if you are constrained in your RFC 1918 space is to use the RFC 6598 CGNAT CIDR block (100.64.0.0/10) for Pods. That is meant to be used for “Carrier Grade NAT” off the Internet and so not be publicly used/routable — and it is often not already used in your business unless you are an ISP. And that /10 is enough to buy you another 126 x /17 Pod CIDR ranges — enough for 126 clusters each with up to 128 Nodes even in the ‘subnet hungry’ GKE if you can use it in your organization.
AWS has a blog post on how to do this here.
And GCP has documentation around it here.
This CGNAT space is often blocked or at least not advertised by many routers and is at best a workaround — one that makes your solution/network more complicated (you’ll need to employ a somewhat complex Transit Gateway in AWS as per their blog post etc.). So, it only makes sense if you are truly out of IPv4 address space to use. And when you consider that there are nearly 18 million private in the ‘normal’ RFC1918 IPs, it should only really be required for large enterprises who truly have enough devices and workloads to exhaust them all.
IPv6
And if you are truly impacted by IPv4 exhaustion then there is another alternative — IPv6. AWS EKS supports IPv6-only addresses for their Pods — while GKE appears today to ‘just’ support a dual-stack (which doesn’t solve our IPv4 challenges). This has its own challenges (6-to-4 NATing etc.) — but it feels like it is the ‘true’ solution if your IP constrained as it solves that problem permanently by moving to a nearly unlimited pool of private IPs.
AWS has documentation on how to do IPv6 only addressing for Pods here.
While GKE’s dual-stack approach is documented here.
Getting both EKS and GKE working with IPv6 and comparing the two might be a whole future blog post itself. Would you all be interested in seeing that one?
Conclusion
I hope that has given you a good summary of the differences you can expect between EKS and GKE when it comes to networking.
For the next blog post in the series, I’ll be getting into the differences in setting up Ingress and associated managed Application Load Balancers in each.
